1 INTRODUÇÃO
Nos últimos anos, a Inteligência Artificial (IA) passou por uma transformação significativa, evoluindo de sistemas simples, que apenas processam informações, para agentes capazes de aprender, tomar decisões e executar tarefas de forma autônoma. Ao contrário das primeiras implementações de IA, que eram limitadas a funções específicas e reativas, os novos agentes de IA são capazes de estruturar fluxos de trabalho, adaptar-se a diferentes contextos e agir de maneira proativa, otimizando processos em diversas áreas.
Segundo Gates (2023), nos próximos cinco anos a interação com a tecnologia será radicalmente transformada. Em vez de alternar entre aplicativos para tarefas específicas, os usuários utilizarão comandos em linguagem natural, enquanto agentes de IA coordenarão e executarão ações de forma integrada e contextualizada. Essa visão é corroborada por Hendrycks (2024), que prevê agentes autônomos como interfaces inteligentes e generalistas, mediando a interação entre usuários e sistemas computacionais, irão proporcionar experiências mais fluídas, seguras e adaptativas.
Em consonância com essa perspectiva, o Gartner (2023) aponta a IA "Agêntica" como uma das principais tendências tecnológicas dos próximos anos. Estima-se que, até 2028, 33% dos aplicativos empresariais incluirão agentes de IA, e pelo menos 15% das decisões corporativas diárias serão tomadas autonomamente. Esse avanço inaugura uma nova fase da IA, na qual modelos baseados em Large Language Models (LLMs) deixam de apenas processar dados e passam a estruturar e executar fluxos de trabalho, viabilizando a transformação digital mencionada por Gates.
A adoção desses agentes representa uma mudança na interação com sistemas digitais e amplia as possibilidades para a Ciência da Informação (CI). Eles atuam como facilitadores na recuperação e entrega contextualizada de dados, automatizando decisões e adaptando-se a diferentes contextos. Segundo Deschamps e Martins (2024), acredita-se que podemos utilizar ferramentas de IA Generativa (Gen AI) em demandas acadêmicas-científicas. Essa utilização requer excelente competência em informação, portanto, urge a necessidade de as pessoas desenvolverem habilidades informacionais, inclusive sob a perspectiva da ética da informação, tendo em vista serem capazes de utilizar o conteúdo sintetizado por ferramentas e utilizá-las de forma assertiva.
Este artigo analisa o uso de agentes de IA na CI, com foco na leitura e análise automatizada de artigos científicos. A proposta destaca como esses agentes, ao operarem com LLMs, podem estruturar o conhecimento extraído da literatura, apoiar a governança da informação e otimizar a tomada de decisões em contextos acadêmicos.
Apesar dos avanços, a implementação prática desses agentes na CI ainda enfrenta desafios estruturais e conceituais. Estudos como o de (2021) destacam que o contexto de aplicação é fundamental para sua eficácia. Pesquisas recentes também apontam a necessidade de desenvolver competências informacionais específicas para o uso ético e crítico dessas tecnologias.
Após esta introdução, o artigo está organizado em cinco seções interdependentes, que buscam responder à seguinte questão central: de que forma agentes baseados em IA podem contribuir para superar lacunas na mediação e no tratamento automatizado da informação científica? A Seção 2 apresenta o referencial teórico, abordando a evolução dos agentes e suas interfaces com os fundamentos epistemológicos da Ciência da Informação. A Seção 3 detalha os procedimentos metodológicos, incluindo a modelagem dos agentes, os critérios de seleção dos dados e as estratégias de análise. A Seção 4 expõe e discute os principais resultados obtidos. Por fim, a Seção 5 traz as considerações finais, destacando as contribuições do estudo, suas limitações e possíveis desdobramentos para pesquisas futuras.
2 REVISÃO DE LITERATURA
A evolução da Inteligência Artificial (IA) tem transformado a CI, reconfigurando seus fundamentos teóricos e práticos. A adoção de modelos de linguagem natural, especialmente os baseados em aprendizado profundo, tem ampliado a automatização de processos informacionais, como organização e recuperação de dados.
Nesse contexto, os agentes inteligentes, que simulam competências cognitivas, têm otimizado fluxos de trabalho e levantado questões éticas e epistemológicas sobre o uso da informação. Segundo Moreira, Nascimento e Ribeiro (2023), sistemas como a IA desafiam concepções tradicionais de autoria e validação do conhecimento, exigindo uma reflexão crítica da comunidade científica.
Esta seção discute as principais características desses agentes e sua interseção com os fundamentos da Ciência da Informação, destacando seu papel como mediadores e catalisadores da inovação no ecossistema informacional.
2.1 Agentes de Inteligência Artificial
De acordo com Lanham (2024), um agente é definido como uma entidade que exerce influência, produz efeitos ou atua como meio para alcançar objetivos específicos. Esta definição remete à concepção filosófica de agência, discutida por pensadores como Aristóteles e Hume. Aristóteles associava a ação intencional à capacidade de agir de maneira racional e deliberada, enquanto Hume enfatizava a adaptação e o aprendizado baseados na experiência. Nos agentes de IA, essa dualidade se reflete na combinação entre raciocínio lógico e aprendizado adaptativo, permitindo que os agentes atuem de maneira autônoma tanto por meio de regras predefinidas quanto pela aprendizagem a partir de dados e interações passadas.
Com base nesse referencial teórico, torna-se crucial contextualizar as diferentes aplicações contemporâneas da Inteligência Artificial, especialmente em relação ao papel funcional de cada tecnologia nos sistemas informacionais. Para isso, é fundamental distinguir entre IA Generativa e Agentes de Inteligência Artificial. Essa distinção é sintetizada de forma esquemática no Quadro 1 – Diferença entre IA Generativa e Agentes Inteligentes, com o objetivo de destacar as diferenças essenciais entre essas abordagens.
| Aspecto | Agentes de IA | Gen AI |
|---|---|---|
| Autonomia | Sistemas autônomos ou semiautônomos que executam tarefas específicas dentro de um sistema ou processo. | Modelos de IA que geram novos conteúdos, como texto, imagens e código, a partir de entradas do usuário. |
| Interação com o usuário | Podem atuar diretamente, como assistentes, ou autonomamente, tomando decisões sem intervenção humana. | Interagem principalmente por meio de prompts, respondendo com conteúdo gerado automaticamente. |
| Objetivo Principal | Automatizar decisões, otimizar processos e adaptar fluxos de trabalho com base em dados contextuais. | Criar conteúdos novos e coerentes baseados em padrões aprendidos a partir de grandes volumes de dados |
| Autonomia | Variável: pode exigir aprovação do usuário ou operar de forma independente. | Depende de entradas externas e não toma decisões estratégicas por conta própria. |
| Capacidade de aprendizado | Aprendem com interações e ajustam seu desempenho ao longo do tempo. | Baseiam-se em modelos treinados previamente e não aprendem continuamente com novas interações. |
| Exemplos | Assistentes virtuais, sistemas de recomendação, chatbots que tomam decisão | Modelos de linguagem como ChatGPT, DALL·E e ferramentas de geração de código. |
| Aplicações | Gestão de processos, automação de tarefas, otimização de fluxos de trabalho. | Criação de texto, imagens, códigos e outras formas de conteúdo gerado automaticamente. |
| Riscos e desafios | Questões éticas e de segurança relacionadas à autonomia na tomada de decisões. | Riscos de viés, geração de informações imprecisas e uso indevido de conteúdos gerados. |
Fonte: Elaborado pelos autores (2025).
Após a diferenciação entre IA Generativa e Agentes de Inteligência Artificial, é necessário aprofundar a compreensão sobre a natureza e funcionamento desses agentes no contexto da IA. Esses sistemas, com diferentes graus de autonomia, são projetados para realizar tarefas específicas em ambientes computacionais dinâmicos. Por meio de mecanismos de percepção, decisão e ação, os agentes de IA interagem com o ambiente, adaptando-se a mudanças e aperfeiçoando continuamente seu desempenho. Tais agentes operam com arquiteturas que combinam processamento simbólico, aprendizado de máquina e inferência contextual, o que lhes confere a capacidade de lidar com tarefas complexas de forma eficaz. Sua capacidade de aprendizado contínuo não se limita a simples reações a estímulos, mas envolve tomadas de decisão proativas e otimizadas, sempre alinhadas a metas previamente estabelecidas.
Russell et al. (2021) definem um agente de IA como "qualquer entidade que perceba seu ambiente por meio de sensores e atue sobre esse ambiente por meio de atuadores", ressaltando que a inteligência do agente está diretamente relacionada à sua capacidade de escolher ações que maximizem seu desempenho ao longo do tempo. Nesse sentido, os agentes de IA podem atuar de forma autônoma ou por meio de proxies, componentes intermediários que interpretam comandos e ajustam as ações dos agentes conforme o contexto. Essa arquitetura favorece a adaptabilidade e o desempenho contínuo. A autonomia, elemento central na definição de agentes inteligentes, possibilita a execução de tarefas complexas com eficiência, muitas vezes superando a capacidade humana em velocidade e precisão. Bandeira e Tortato (2024) reforçam que a capacidade de aprendizado contínuo e de aprimoramento das decisões é um elemento essencial para o papel estratégico dos agentes de inteligência artificial em ambientes digitais.
Analogamente à concepção filosófica de agência, que remonta à ideia aristotélica de ação orientada por finalidade (telos) e à visão de Hume sobre a conexão entre crenças e motivações, os agentes de inteligência artificial, embora desprovidos de intencionalidade ou consciência, operam com base em comportamentos dirigidos a objetivos específicos. Nesse contexto, o desenvolvimento desses agentes acompanha a evolução tecnológica recente, refletindo a crescente incorporação da IA nos sistemas de organização, recuperação e gestão da informação.
Para entender as nuances da agência na IA, é necessário observar suas propriedades funcionais, como reatividade, proatividade e socialidade, conceitos inicialmente abordados por Turing (1950) em seu artigo "Computing Machinery and Intelligence", ao questionar a capacidade das máquinas de interagir de forma inteligente e ampliados por Mitchel (2019). Esses avanços indicam que, ao otimizar processos e resultados organizacionais, os agentes de IA têm um papel crescente nas soluções computacionais dinâmicas e na transformação digital das empresas.
2.2 Interseção entre agentes de Inteligência Artificial e a Ciência da Informação
Esta seção explora a aplicação de agentes de inteligência artificial na Ciência da Informação, destacando suas funcionalidades e integração com práticas informacionais modernas. Esses agentes, além de ferramentas computacionais avançadas, otimizam a eficiência dos sistemas informacionais, exigindo reflexão crítica sobre questões éticas e sociais.
O estudo foca em sistemas que atendem a esses critérios, diferenciando-os de soluções genéricas. A transformação dos processos informacionais por esses agentes é ilustrada na Figura 1: Evolução histórica dos agentes de IA aplicados à Ciência da Informação.
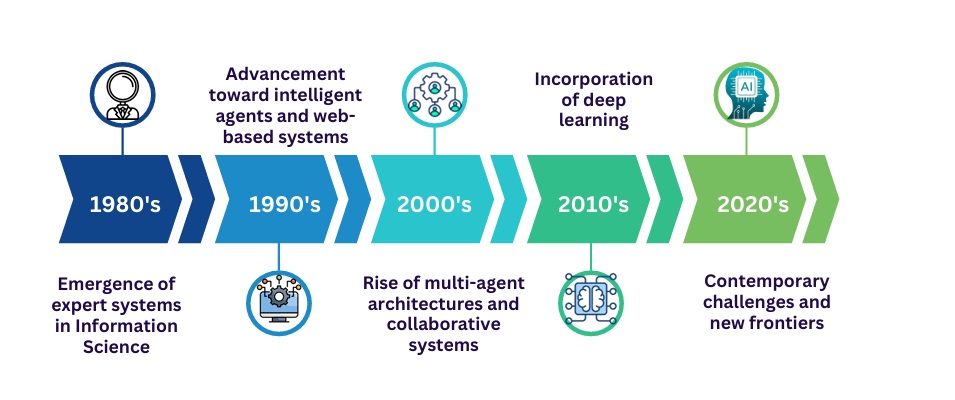
A trajetória dos agentes de IA na Ciência da Informação remonta à década de 1980, quando os primeiros sistemas especialistas, como o PLEXUS (1985) e o SCISOR (1986), foram desenvolvidos. Embora esses sistemas não se qualificassem como agentes inteligentes no sentido estrito — dada a sua limitação a regras fixas e árvores de decisão pré-programadas, sem a capacidade de aprender ou de agir de forma autônoma —, representaram um marco fundamental na demonstração do potencial da automação inteligente para tarefas informacionais complexas, tais como indexação e classificação documental. O avanço desses sistemas pioneiros abriu as portas para o desenvolvimento de agentes mais sofisticados, que, mesmo de forma rudimentar, já eram capazes de emular processos decisórios humanos em contextos específicos.
Na década de 1990, observou-se uma transformação significativa com a emergência dos primeiros agentes de IA com autonomia decisória e capacidade de adaptação ao ambiente. A expansão da World Wide Web foi um fator-chave nesse processo, pois impôs novos desafios ao mesmo tempo em que abriu oportunidades para o desenvolvimento de soluções informacionais baseadas em agentes inteligentes. Projetos pioneiros, como o SHOE (1996) e o Ontobroker (1997), exploraram arquiteturas orientadas a agentes para a organização do conhecimento em ambientes digitais distribuídos, estabelecendo um marco na maneira como as informações seriam processadas, estruturadas e recuperadas em plataformas digitais. Nesse contexto, a teoria da atividade, formulada por Engeström (1987), consolidou-se como uma importante referência teórica para a compreensão dos processos de mediação informacional realizados por esses agentes, ao considerar os sistemas sociotécnicos nos quais eles operavam.
No final da década de 1990, os primeiros agentes colaborativos, como o CiteSeer (1998), começaram a demonstrar o enorme potencial da automação no campo da organização da informação científica. O CiteSeer utilizava técnicas automatizadas de indexação e recuperação de artigos acadêmicos, antecipando a consolidação, no início do novo milênio, das arquiteturas multiagente na Ciência da Informação. Essas novas arquiteturas permitiram a coordenação de sistemas distribuídos e possibilitaram a realização de tarefas complexas, como mineração de dados e descoberta automatizada de conhecimento, ampliando a sofisticação dos agentes de IA nesse campo. Além disso, surgiram iniciativas de recomendação, como os sistemas de filtragem colaborativa da Amazon (2003) e os assistentes digitais voltados à pesquisa acadêmica, conforme discutido por Baeza-Yates e Ribeiro-Neto (2011), que indicaram uma crescente tendência de personalização e mediação inteligente na gestão do acesso à informação.
Ao longo da década de 2010, a introdução de técnicas de aprendizado profundo (deep learning) transformou de maneira substancial os agentes de IA permitindo-lhes aprender continuamente a partir de grandes volumes de dados e tomar decisões cada vez mais sofisticadas e autônomas. Exemplos de agentes, como o Semantic Scholar (2015) e o Iris.ai (2016), ampliaram de forma significativa as possibilidades de mediação informacional inteligente, alterando a forma como a informação acadêmica era processada, indexada e recomendada. Nesse novo cenário, a teoria da cognição distribuída (Hollan; Hutchins; Kirsh, 2000) adquiriu uma importância renovada, pois forneceu um referencial teórico fundamental para a compreensão dos ecossistemas híbridos humano-máquina, que são característicos do funcionamento dos agentes de IA em ambientes digitais cada vez mais complexos.
Diante dos desafios técnicos, epistemológicos e éticos mencionados (Zuboff, 2019), este estudo adota uma abordagem metodológica que visa superar as complexidades da implementação de agentes de IA na Ciência da Informação.
A seguir, detalha-se a metodologia aplicada para o desenvolvimento e avaliação da arquitetura computacional proposta, com foco na análise automatizada de artigos científicos, considerando as questões de escalabilidade e ética.
3 METODOLOGIA
Este estudo, de natureza aplicada, tem como objetivo desenvolver e avaliar uma arquitetura computacional baseada em agentes de inteligência artificial para análise automatizada de artigos científicos na área da Ciência da Informação.
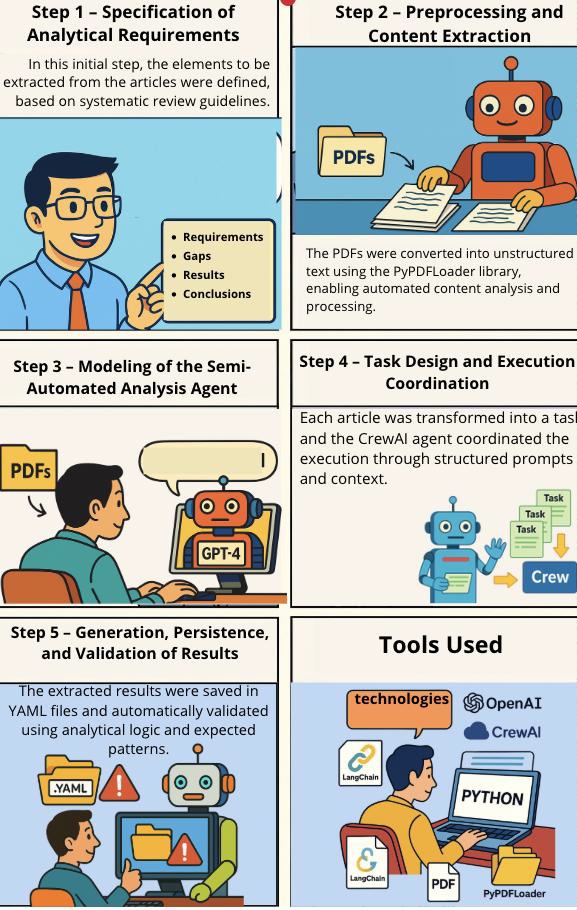
Com abordagem qualitativa, exploratória e descritiva, a pesquisa foi estruturada como um estudo de caso tecnológico com validação prática. Utilizou-se inteligência artificial generativa para extrair informações em linguagem natural, organizadas em cinco etapas principais detalhadas na Figura 2 – Etapas da Pesquisa.
3.1 Especificação dos requisitos analíticos
A etapa inicial da pesquisa consistiu na delimitação das categorias analíticas a serem extraídas dos artigos científicos selecionados, fundamentando-se em diretrizes metodológicas consagradas no âmbito da revisão sistemática da literatura. Foram definidas oito categorias analíticas que orientaram a extração e sistematização dos dados: (i) objetivos da pesquisa; (ii) lacuna teórica ou científica identificada; (iii) metodologia adotada; (iv) principais achados; (v) limitações reconhecidas pelos autores; (vi) conclusões apresentadas; (vii) recomendações para investigações futuras; e (viii) avaliação crítica do estudo.
Complementarmente à definição do escopo analítico, estabeleceu-se o uso de uma linguagem neutra, objetiva e predominantemente descritiva, com a exclusão deliberada de adjetivações superlativas e juízos de valor. Tal orientação visa assegurar a imparcialidade na apresentação dos dados, reforçando a clareza argumentativa e a conformidade com os princípios de rigor e transparência que regem a produção científica de excelência.
A partir dessa estrutura analítica previamente definida, procedeu-se à fase de pré-processamento dos documentos e à subsequente extração sistemática do conteúdo, conforme descrito na seção a seguir.
3.2 Pré-processamento e extração de conteúdo
Dando continuidade à estrutura metodológica delineada, procedeu-se ao pré-processamento dos documentos científicos com vistas à organização e preparação dos dados textuais para análise sistemática. Os artigos, previamente armazenados em formato digital (PDF), foram submetidos a uma etapa de extração automatizada de conteúdo utilizando a biblioteca PyPDFLoader, integrante do ecossistema langchain_community, amplamente empregada em processos de mineração e tratamento de informações textuais.
Essa tecnologia viabilizou a decomposição dos documentos em unidades textuais coerentes, respeitando a estrutura lógica e semântica das páginas originais. A segmentação criteriosa dos textos assegurou a preservação da integridade informacional, aspecto fundamental para garantir a rastreabilidade e a confiabilidade dos dados extraídos.
A organização dos conteúdos em blocos estruturados favoreceu a aplicação posterior de técnicas de processamento de linguagem natural (Natural Language Processing – NLP), possibilitando o alinhamento preciso entre os dados empíricos e as categorias analíticas definidas anteriormente. Tal abordagem reflete as boas práticas de curadoria e tratamento de dados no âmbito da Ciência da Informação, especialmente no que tange à gestão, à representação e à recuperação de informações em ambientes digitais.
3.3 Modelagem do agente de análise
Na sequência do fluxo metodológico, a terceira etapa concentrou-se na modelagem de um agente computacional especializado, concebido para desempenhar a função de Analista de Artigos Científicos. A implementação desse agente foi realizada por meio da biblioteca CrewAI, um framework voltado à orquestração de agentes autônomos baseados em modelos de linguagem natural. Essa biblioteca possibilita a criação de agentes com perfis específicos, capazes de atuar de forma colaborativa ou individual na execução de tarefas cognitivas complexas, mediante a configuração de objetivos, papéis e comportamentos analíticos customizados.
No contexto desta pesquisa, a CrewAI foi empregada de maneira integrada ao modelo GPT-4, acessado por meio da interface langchain_openai, permitindo o desenvolvimento de um agente com escopo de atuação bem definido. A configuração contemplou a definição explícita dos objetivos analíticos, o contexto de aplicação (análise de literatura científica) e diretrizes metodológicas alinhadas às categorias estabelecidas na etapa anterior de extração e curadoria dos dados.
Com o intuito de assegurar maior controle sobre a conduta interpretativa do agente e preservar a coerência metodológica da análise, optou-se por desabilitar a funcionalidade de delegação de tarefas entre múltiplos agentes. Essa decisão visou mitigar variações heurísticas indesejadas, assegurando a estabilidade cognitiva da instância analítica e promovendo maior uniformidade na aplicação dos critérios de interpretação textual.
3.4 Design das tarefas e execução automatizada
A quarta etapa consistiu no delineamento das tarefas cognitivas e na execução automatizada das análises sob responsabilidade do agente computacional previamente modelado. Cada artigo científico foi concebido como uma unidade analítica independente, sendo encapsulado como uma instância da classe Task, conforme a arquitetura operacional da biblioteca CrewAI.
Nesse contexto, adotou-se um modelo de fragmentação textual controlada, no qual cada tarefa foi associada a um extrato do documento com limite de até 5.000 caracteres, valor empiricamente definido para otimizar o desempenho do modelo de linguagem e preservar a coesão semântica do conteúdo analisado. Essa granularidade permitiu ao agente processar os dados em blocos suficientemente informativos, mantendo o equilíbrio entre carga cognitiva e contexto interpretativo.
As tarefas foram alocadas ao agente de análise dentro da estrutura gerencial do objeto Crew, o qual opera como núcleo coordenador das atividades dos agentes autônomos. A execução das análises foi iniciada por meio do método kickoff(), que atua como ponto de disparo da interação entre agente e conteúdo, ativando o ciclo analítico conforme os parâmetros de configuração previamente definidos.
Esse processo garantiu a replicabilidade das análises e a rastreabilidade dos resultados, assegurando aderência às boas práticas de sistematização e controle metodológico exigidas em estudos computacionais na área da Ciência da Informação. Além disso, o uso da estrutura Crew como mecanismo de gerenciamento das tarefas analíticas conferiu robustez ao fluxo de execução, permitindo o acompanhamento preciso da atuação do agente e o registro dos outputs gerados em cada interação.
3.5 Geração e validação dos resultados
A etapa final do fluxo automatizado consistiu na sistematização e validação dos resultados produzidos pelo agente computacional. Após a execução de cada tarefa analítica, os dados extraídos foram serializados no formato YAML (YAML Ain't Markup Language), escolhido por sua legibilidade estrutural e ampla adoção em fluxos de interoperabilidade e persistência de dados. A codificação foi realizada em UTF-8, garantindo a integridade lexical e a compatibilidade com sistemas de armazenamento e leitura textual em múltiplos ambientes computacionais.
As saídas geradas foram automaticamente armazenadas em um diretório previamente definido, com nomenclatura padronizada e controle de versionamento, assegurando a rastreabilidade dos resultados. Para cada operação de escrita, o sistema executa uma verificação automatizada de integridade, emitindo mensagens de status e, em caso de erro, registrando logs informativos com dados técnicos para diagnóstico e auditoria.
Com o objetivo de assegurar a conformidade metodológica da atuação do agente, foi conduzida uma auditoria manual realizada pelos autores da pesquisa. Essa auditoria consistiu na verificação amostral dos arquivos gerados, com especial atenção ao alinhamento entre os resultados extraídos e os parâmetros e diretrizes analíticas previamente definidos na etapa de configuração do agente. Foram observados aspectos como: aderência às categorias analíticas, consistência descritiva, fidelidade ao conteúdo textual original e respeito aos limites semânticos estabelecidos.
Adicionalmente, destaca-se que a atuação humana não se restringiu à auditoria técnica do sistema, mas se estenderá, conforme descrito na próxima seção, à validação crítica dos achados. Essa etapa incluirá a análise qualitativa das respostas produzidas pela IA promovendo um processo de verificação cruzada entre inteligência artificial e julgamento humano, assegurando não apenas a robustez técnica, mas também a credibilidade epistemológica dos resultados.
3.6 População e amostragem
A população investigada nesta pesquisa compreende publicações científicas vinculadas ao domínio da Ciência da Informação, com ênfase em estudos que abordam práticas metodológicas de revisão da literatura, representação do conhecimento e tratamento informacional. A amostra, por sua vez, foi composta por dois artigos científicos publicados na RDBCI – Revista Digital de Biblioteconomia e Ciência da Informação, sediada em Campinas, SP.
A seleção foi realizada por meio de amostragem intencional, tendo como critério principal a relevância temática das publicações para os objetivos da pesquisa, bem como a disponibilidade do conteúdo em formato digital integral, condição indispensável para o processamento computacional automatizado.
O objetivo da análise recaiu sobre a verificação da capacidade de um agente de inteligência artificial em interpretar, sintetizar e estabelecer comparações entre publicações científicas, considerando os princípios e os métodos aplicados na área da Ciência da Informação. A escolha por artigos provenientes de um periódico científico reconhecido visou garantir a qualidade metodológica e a representatividade teórica dos documentos, contribuindo para a robustez e a confiabilidade dos resultados obtidos.
3.7 Instrumentos e Técnicas de Coleta e Análise de Dados
O principal instrumento de coleta de dados adotado nesta investigação foi o agente computacional autônomo, desenvolvido e configurado especificamente para esta finalidade, conforme descrito nas seções anteriores. Esse agente foi programado para realizar a extração estruturada de conteúdos textuais a partir dos artigos selecionados, utilizando como referência um modelo de saída padronizado, baseado nas categorias analíticas previamente definidas.
A validação dos dados extraídos foi conduzida por meio de uma análise cruzada com os documentos originais, assegurando a fidelidade semântica das informações e o respeito à integridade autoral. Esse procedimento visou garantir que o agente operasse em conformidade com os princípios éticos e legais de uso de conteúdo acadêmico, evitando distorções interpretativas ou violações de direitos autorais.
A análise dos dados foi realizada sob uma abordagem qualitativa, centrada na verificação da consistência interpretativa, clareza textual e alinhamento às diretrizes analíticas. O processo analítico buscou, portanto, integrar a precisão técnica da extração automatizada com o rigor epistemológico característico da Ciência da Informação, promovendo uma interpretação crítica e contextualizada dos achados.
3.8 Tecnologias e ferramentas utilizadas
A arquitetura computacional desenvolvida para esta pesquisa foi concebida com base em uma abordagem modular, visando à escalabilidade, reprodutibilidade e compatibilidade com pipelines automatizados de análise textual assistida por inteligência artificial. A implementação foi realizada na linguagem de programação Python, versão 3.13, selecionada por sua ampla adoção na comunidade científica e pela robustez de seu ecossistema voltado ao desenvolvimento de aplicações em inteligência artificial e ciência de dados.
A arquitetura é composta por quatro módulos principais, integrados de forma a viabilizar o processamento completo dos artigos científicos, desde a leitura dos arquivos em formato PDF até a geração estruturada dos resultados analíticos. A seguir, a Figura 3 – Arquitetura Computacional, descreve os componentes e suas respectivas funções:
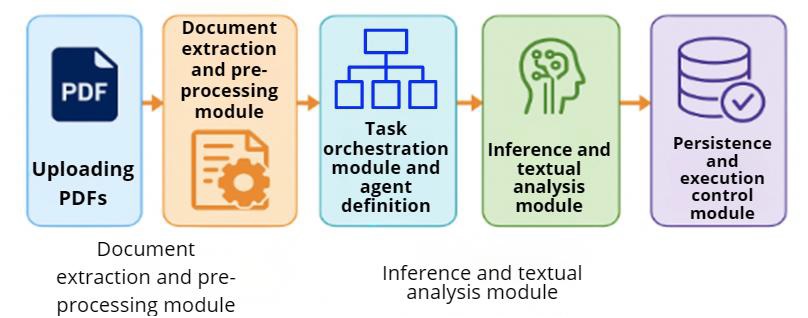
O módulo de extração e pré-processamento foi responsável pela leitura e segmentação dos artigos científicos em formato PDF, utilizando a biblioteca PyPDFLoader, do ecossistema langchain_community. Essa ferramenta permitiu a conversão dos documentos em objetos textuais estruturados, preservando a integridade do conteúdo original.
O módulo de orquestração de tarefas e definição de agentes foi implementado com base na biblioteca CrewAI, possibilitando a modelagem de agentes autônomos e a coordenação de suas ações analíticas. Cada agente foi configurado segundo perfis específicos, definidos em consonância com os requisitos analíticos estabelecidos.
No módulo de inferência e análise textual, a integração com o modelo GPT-4 foi viabilizada por meio da interface langchain_openai, permitindo a geração controlada de respostas a partir de prompts customizados. Este módulo constituiu o núcleo da arquitetura, sendo responsável pela análise semiautomatizada do conteúdo e pela produção de respostas estruturadas, em conformidade com os princípios de linguagem neutra e originalidade.
Por fim, o módulo de persistência e controle de execução foi responsável pela serialização dos resultados em formato YAML, com codificação UTF-8, assegurando rastreabilidade e integridade dos dados. Bibliotecas padrão da linguagem Python foram utilizadas para gerenciar diretórios, verificar a criação de arquivos e emitir mensagens de status ao término de cada operação.
A integração entre esses módulos permitiu a criação de um fluxo de trabalho contínuo e automatizado, desde a ingestão dos documentos até a geração dos resultados estruturados. A arquitetura proposta foi desenhada para ser reutilizável em diferentes contextos analíticos e facilmente adaptável a outras tipologias documentais, demonstrando potencial para apoiar estudos sistemáticos em larga escala com auxílio de agentes baseados em inteligência artificial.
3.9 Considerações éticas e Limitações e controle de viés
Foram adotadas diretrizes éticas rigorosas para garantir a integridade científica. O agente computacional foi explicitamente instruído a evitar qualquer reprodução literal de trechos dos documentos analisados. Estratégias de paráfrase com alta originalidade textual (nível 10/10) foram utilizadas para assegurar conformidade com as boas práticas da produção científica automatizada.
A principal limitação identificada refere-se à dependência das capacidades interpretativas do modelo GPT-4, o que pode resultar em variações na qualidade da extração textual. Para mitigar esse fator, foram aplicadas diretrizes formais de estilo, delimitação de vocabulário e estrutura analítica rígida. A utilização de um modelo de saída padronizado visou reduzir inconsistências e aumentar a replicabilidade da metodologia.
4 RESULTADOS
Esta seção demonstra os resultados obtidos a partir da pesquisa aplicada, conforme a metodologia definida anteriormente. Como detalhado, o objetivo deste estudo, de natureza aplicada, foi o desenvolvimento e a avaliação de uma arquitetura computacional baseada em agentes de inteligência artificial para a análise automatizada de artigos científicos na área da Ciência da Informação. A pesquisa adotou uma abordagem qualitativa, exploratória e descritiva, estruturada como um estudo aplicado e com abordagem tecnológica com validação prática.
Foram realizados dois quadros comparativos, um para cada artigo publicado na RDBCI – Revista Digital de Biblioteconomia e Ciência da Informação | Campinas, SP. O primeiro artigo, intitulado "Inteligência artificial no levantamento bibliográfico em bases de dados científicos: comparando expressões de busca no ChatGPT, Copilot e Gemini", foi analisado por meio de um quadro comparativo específico, e o segundo artigo, "O desenvolvimento tecnológico e de inovação em gestão do conhecimento", foi apresentado em seu próprio quadro.
O primeiro artigo, de autoria de Antônio Carlos Picalho, Gisele Rosa de Oliveira e Adriana Stefani Cativelli, realiza um estudo comparativo entre três ferramentas de inteligência artificial aplicadas à elaboração de estratégias de busca bibliográfica. Já o segundo artigo, de Rafael Gutierres Castanha, Fernanda Bochi dos Santos e Augusto Júnior Macucule, aborda o desenvolvimento e inovação tecnológica na área de gestão do conhecimento, por meio de uma análise patentométrica. Em ambos os estudos, foi realizada uma auditoria humana para verificar a precisão de cada item extraído e comparado, garantindo a confiabilidade dos resultados.
O quadro apresenta três colunas, com a primeira denominada "Dimensão", onde são listadas as diferentes categorias de análise. A segunda coluna, "Análise da IA (Saída - arquivo - YAML)", detalha as respostas geradas pelo agente de inteligência artificial, representadas no formato de arquivo YAML. Já a terceira coluna, "Análise dos Autores", apresenta a interpretação dos autores humanos, permitindo uma comparação entre as saídas da IA e as análises realizadas pelos especialistas. Este formato facilita a visualização e a comparação entre as contribuições do agente de IA e as conclusões dos autores.
| Dimensão | Análise da IA (Saída - arquivo - YAML) | Análise dos Autores |
|---|---|---|
| Objetivos | O estudo teve como objetivo examinar o potencial de três ferramentas de inteligência artificial (ChatGPT-4, Copilot e Gemini) na execução de comandos diretos relacionados à elaboração de expressões de busca em bases de dados científicos. | O agente identificou corretamente o objetivo do artigo, validado pelos trechos: 'O objetivo deste artigo não foi trazer uma contribuição teórica para o campo [...], mas sim, executar o potencial de três ferramentas de IA ao executar comandos diretos relacionados à formação de expressões de busca e .... expressões de busca'. |
| Lacuna (Gap) | O estudo abordou a lacuna existente na compreensão do desempenho de diferentes ferramentas de inteligência artificial na elaboração de expressões de busca, uma tarefa crucial em bibliotecas e serviços de referência. | O agente identificou corretamente a lacuna do estudo, validada por trechos que destacam a ausência de pesquisas comparativas sobre o uso de IA generativa na construção de expressões de busca, como: 'a pesquisa apresenta caráter inovador ao expor na prática o potencial de uso das ferramentas de IA Generativa...' e a demanda crescente por apoio na elaboração de estratégias de busca. |
| Metodologia | O estudo foi caracterizado como pesquisa aplicada, empírica e de método comparativo. Foram selecionadas três ferramentas de inteligência artificial: Chat GPT -4, Copilot e Gemini. Descritores, termos livres e expressões de busca foram selecionados com base em um objetivo fictício de pesquisa. Prompts foram usados para indicar o que as ferramentas deveriam retornar em relação à pesquisa e a análise focou em avaliar o entendimento dos comandos e a existência ou não de erros de sintaxe. | O agente identificou corretamente a metodologia como "pesquisa aplicada, empírica e de método comparativo". No entanto, em futuras versões, poderiam ser incorporadas ações que evidenciem com maior clareza a "veracidade" e a "operacionalização do caráter empírico", como a explicitação de "critérios de avaliação", "métricas de comparação" e "validação externa dos outputs gerados pelas ferramentas". |
| Resultados | O estudo encontrou que, em solicitações mais mecânicas, o ChatGPT e o Copilot tiveram melhor desempenho, com pouca ou nenhuma distorção. No entanto, em solicitações mais contextuais, o Gemini apresentou melhores resultados. Foram observados erros em operadores booleanos e outros operadores avançados de pesquisa, além da execução de ações não solicitadas. | O artigo evidencia variações no desempenho das ferramentas de IA: ChatGPT e Copilot se saíram melhor em tarefas mecânicas, enquanto o Gemini teve destaque em comandos contextuais. Também foram relatados erros em operadores booleanos e ações não solicitadas. O agente identificou corretamente esses aspectos, no entanto, sua resposta foi descritiva, sem enfatizar a relevância crítica dessa limitação para a aplicabilidade prática. |
| Limitações | O estudo reconheceu que, apesar de as ferramentas de inteligência artificial serem úteis para tarefas repetitivas e corretivas, elas não produzem expressões de busca de alta sensibilidade por si só, necessitando de supervisão e adequações antes da estratégia ser empregada. | O agente identificou corretamente a limitação central do estudo ao reconhecer que as ferramentas de inteligência artificial, embora úteis, não geram expressões de busca de alta sensibilidade sem supervisão. Sua análise está alinhada ao texto, que define as IAs como "grandes aliadas", mas que "necessitam de supervisão e adequações antes da estratégia ser empregada". A resposta reflete com precisão essa limitação metodológica, considerada uma das conclusões principais do trabalho. |
| Conclusão | O estudo concluiu que as ferramentas de inteligência artificial, embora úteis, ainda necessitam de supervisão e ajustes para produzir expressões de busca de alta sensibilidade, destacando a importância do papel humano na elaboração de estratégias de busca. | O agente reconheceu corretamente a necessidade de supervisão humana, mas sua análise foi superficial ao não aprofundar um ponto central do estudo: a importância do papel dos profissionais da informação e da interação entre humanos e IA nas estratégias de busca. |
| Futuras Pesquisas | O estudo sugere que pesquisas futuras poderiam focar em melhorar a sensibilidade das ferramentas de inteligência artificial na elaboração de expressões de busca, bem como explorar a integração dessas ferramentas em outros aspectos dos serviços de referência em bibliotecas. | O agente identificou parte das sugestões do estudo, como o aprimoramento das IAs e sua integração em serviços de referência, mas omitiu pontos importantes, como a comparação com outras IAs científicas e a necessidade de treinamento, o que limita o escopo da análise. |
| Avaliação Crítica | O estudo forneceu uma análise útil do desempenho de diferentes ferramentas de inteligência artificial na elaboração de expressões de busca. No entanto, poderia ter se beneficiado de uma amostra maior de expressões de busca e de uma análise mais aprofundada dos erros encontrados. Além disso, a inclusão de outras ferramentas de inteligência artificial poderia ter proporcionado uma comparação mais abrangente. | O agente identificou corretamente limitações técnicas, como a necessidade de uma amostra maior e de incluir outras ferramentas de IA, mas sua análise foi superficial. Como autores, destacamos a relevância do tema, o papel humano na mediação informacional e sugestões práticas para pesquisas futuras — pontos ausentes na resposta automatizada, que ainda carece de profundidade interpretativa. |
Fonte: Dados da Pesquisa (2025).
O agente analisado no estudo demonstrou um desempenho satisfatório na extração das informações centrais do artigo, reconhecendo corretamente os objetivos, a lacuna, a metodologia e as principais conclusões. Validou, com base em trechos explícitos, que o artigo visava "examinar o potencial de três ferramentas de IA ao executar comandos diretos relacionados à formação de expressões de busca" e que a lacuna principal era a ausência de estudos comparativos na área. A metodologia foi adequadamente identificada como "pesquisa aplicada, empírica e de método comparativo". Contudo, o agente não aprofundou a análise sobre a "veracidade" e a "operacionalização do caráter empírico", sem detalhar critérios, métricas ou formas de validação utilizadas.
Nos resultados, o agente reconheceu os achados principais — como o desempenho distinto das ferramentas em comandos mecânicos e contextuais —, mas a análise permaneceu descritiva, sem categorização analítica ou indicadores de desempenho. Além disso, a ausência de representações visuais e de uma estrutura comparativa limitou a clareza e utilidade da apresentação. As limitações do estudo foram bem identificadas, especialmente em relação à necessidade de supervisão humana, embora a importância dessa mediação tenha sido pouco explorada pelo agente.
As sugestões para pesquisas futuras foram parcialmente abordadas, sem considerar comparações com outras IAs voltadas para pesquisa científica ou a necessidade de treinamentos específicos. Em resumo, a análise automatizada mostrou coerência técnica, mas ainda carece de profundidade conceitual, ressaltando a importância da análise humana para interpretações mais amplas e críticas.
Agora, passaremos à análise do Artigo 2, intitulado "O desenvolvimento tecnológico e de inovação em gestão do conhecimento", que explora aspectos tecnológicos no campo da gestão do conhecimento. A seguir, os detalhes do estudo.
| Dimensão | Análise da IA (Saída - arquivo - YAML) | Análise dos Autores |
|---|---|---|
| Objetivos | O principal objetivo do estudo foi analisar o desenvolvimento tecnológico e a inovação na gestão do conhecimento, especificamente por meio da produção de patentes na área. | Os autores confirmam que o objetivo do artigo foi corretamente identificado: analisar o desenvolvimento tecnológico e a inovação na gestão do conhecimento com base na produção de patentes. O objetivo é claramente definido na introdução: "O objetivo central é analisar o desenvolvimento tecnológico e a inovação a partir das patentes sobre gestão do conhecimento". |
| Lacuna (Gap) | O estudo abordou a lacuna existente na compreensão do papel das patentes na gestão do conhecimento e como elas contribuem para o desenvolvimento tecnológico e a inovação. | O agente identificou corretamente a lacuna do estudo, evidenciada por trechos que ressaltam a necessidade de compreender o papel das patentes na gestão do conhecimento e sua contribuição para o desenvolvimento tecnológico e a inovação. Essa lacuna é explicitada no problema de pesquisa, nos objetivos e reforçada nas conclusões, que destacam a importância de analisar a produção patentária para identificar tendências e orientar estratégias futuras na área. |
| Metodologia | O estudo utilizou uma abordagem patentométrica, com o termo de busca 'knowledge management' na base de dados Derwent Index Innovation. Foram coletados dados relacionados a patentes sobre gestão do conhecimento, totalizando 1311 resultados. A análise incluiu a evolução temporal da solicitação de patentes, as principais áreas das patentes, a concorrência entre as classificações internacionais de patentes e a cooperação entre organizações ou inventores. | O agente corretamente identificou que o estudo adota uma abordagem patentométrica para analisar a produção de patentes em gestão do conhecimento. No entanto, cometeu erros conceituais ao incluir informações da seção de resultados na descrição metodológica, como os códigos de classificação e organizações recorrentes. Além disso, não detalhou aspectos essenciais da operacionalização, como critérios de seleção, filtragem e categorização dos dados extraídos do Derwent Index Innovation, evidenciando uma compreensão incompleta dos procedimentos metodológicos. |
| Resultados | O estudo encontrou um aumento na solicitação de patentes em Gestão do Conhecimento entre 1992 e 2024. As áreas de conhecimento de maior concentração são engenharia e Ciência da Computação e os códigos de classificação internacional de patentes mais representativos são: G06N, G06F, G06Q e H04L. As principais cooperações ocorreram entre as organizações IBMC, Hitachi Ltd., Hewlett-Packard Company e Oracle. | O agente identificou corretamente os principais resultados do estudo, como o crescimento das patentes em gestão do conhecimento, as áreas de maior concentração, os códigos de classificação mais frequentes e as principais colaborações institucionais. No entanto, sua análise permaneceu descritiva, sem aprofundar implicações ou contextualizar os achados no campo da inovação e da gestão do conhecimento. |
| Limitações | O estudo não discutiu explicitamente suas limitações, mas é possível inferir que a análise se restringiu à base de dados Derwent Index Innovation, o que pode ter excluído patentes relevantes de outras bases de dados. | O agente reconheceu corretamente a limitação referente ao uso exclusivo da base Derwent, mas não abordou a ausência de uma análise crítica dos achados. A apresentação dos resultados foi descritiva, sem explorar suas implicações para a gestão do conhecimento. A avaliação automatizada foi adequada tecnicamente, mas limitada quanto à profundidade interpretativa. |
| Conclusão | O estudo concluiu que a solicitação de patentes em gestão do conhecimento está em pleno crescimento, com algumas organizações se destacando mais do que outras. As patentes referem-se principalmente ao desenvolvimento de artefatos e/ou processos industriais relacionados à Engenharia e Computação. | O agente abordou corretamente os principais pontos da conclusão, como o crescimento das solicitações de patentes e a predominância das áreas de Engenharia e Computação. No entanto, a conclusão poderia ser enriquecida com uma análise dos fatores que impulsionam esse crescimento, bem como uma reflexão crítica sobre as organizações em destaque e a relevância estratégica das áreas tecnológicas envolvidas. |
| Futuras Pesquisas | O estudo sugere uma análise mais aprofundada das patentes em gestão do conhecimento, possivelmente expandindo a pesquisa para outras bases de dados e considerando outras variáveis, como o impacto dessas patentes no mercado e na sociedade. | O agente identificou corretamente direções para pesquisas futuras, como a ampliação para outras bases de dados e o aprofundamento em variáveis como impacto social e econômico. Contudo, não abordou sugestões importantes do estudo, como a análise da Hélice Tríplice, a comparação entre países desenvolvidos e em desenvolvimento, e a investigação em setores emergentes. Esses pontos são fundamentais para a compreensão da gestão do conhecimento e sua relação com a inovação em diferentes contextos. |
| Avaliação Crítica | O estudo fornece uma visão interessante sobre o papel das patentes na gestão do conhecimento. No entanto, a falta de uma discussão explícita sobre as limitações da pesquisa e a ausência de uma análise mais aprofundada do impacto dessas patentes limitam a generalização dos resultados. | O agente identificou corretamente os principais pontos da conclusão, mas não aprofundou as implicações dos achados nem mencionou a ausência de uma discussão crítica sobre as limitações. Sua análise foi adequada, porém limitada em termos interpretativos, evidenciando a necessidade de mediação humana para uma leitura mais abrangente. |
Fonte: Dados da Pesquisa (2025).
No segundo artigo, o agente identificou corretamente os objetivos, a lacuna, a metodologia e as conclusões, validando a intenção de analisar o desenvolvimento tecnológico e a inovação na gestão do conhecimento por meio da produção de patentes. No entanto, a análise do agente não aprofundou a operacionalização da pesquisa, como os critérios de seleção de dados, e deixou de detalhar aspectos importantes, como a "veracidade" da pesquisa. Nos resultados, o agente reconheceu corretamente os principais achados, mas a análise foi descritiva e não contextualizou adequadamente os achados no campo da inovação e gestão do conhecimento. A ausência de categorização analítica e representações visuais limitou a clareza dos resultados. O agente também reconheceu as limitações do estudo, como o uso exclusivo da base de dados Derwent, mas não explorou suas implicações. As sugestões para pesquisas futuras foram corretamente apontadas, mas o agente deixou de abordar questões cruciais, como a análise da Hélice Tríplice e a comparação entre países desenvolvidos e em desenvolvimento. De modo geral, a análise foi tecnicamente coerente, mas faltou maior profundidade conceitual, o que evidencia a necessidade de uma interpretação humana mais crítica.
Em relação à avaliação geral dos dois artigos, os resultados obtidos pelo agente de inteligência artificial revelam tanto as potencialidades quanto as limitações no uso de tais tecnologias para a interpretação e síntese de artigos científicos na área da Ciência da Informação. Embora o desempenho do agente tenha sido satisfatório em muitos aspectos, como a identificação dos objetivos e a extração das informações centrais, a análise dos resultados mostrou que há uma necessidade de maior profundidade interpretativa e contextualização. A ausência de uma abordagem mais crítica nas limitações e nas sugestões para futuras pesquisas também destaca a importância da mediação humana, que enriquece as interpretações e amplia as conclusões. A seguir, a seção de discussão irá explorar essas questões, abordando as implicações dos achados e as possibilidades de aprimoramento das metodologias utilizadas.
5 CONCLUSÃO
Este estudo teve como objetivo propor e avaliar a aplicação de um agente de inteligência artificial (IA), baseado em modelos de linguagem, para realizar a análise automatizada de artigos científicos no campo da Ciência da Informação. Os resultados demonstraram que o agente foi capaz de identificar corretamente elementos estruturais relevantes dos artigos, como objetivos, lacuna de pesquisa, metodologia, resultados e sugestões para estudos futuros. Essa capacidade confirma o potencial da IA como ferramenta de apoio na execução de tarefas repetitivas e estruturadas, como a leitura inicial e a categorização de dados textuais em revisões sistemáticas da literatura.
A análise crítica, no entanto, evidenciou limitações importantes. A atuação do agente revelou-se descritiva e pouco aprofundada em aspectos analíticos e conceituais, especialmente na interpretação das implicações dos achados e na formulação de inferências mais complexas. Esses pontos demonstram que, embora a tecnologia ofereça suporte relevante ao trabalho do pesquisador, sua atuação ainda exige mediação humana qualificada, capaz de agregar densidade teórica, crítica e contextual à análise automatizada.
Do ponto de vista teórico, este trabalho contribui para o avanço das discussões sobre a integração entre sistemas inteligentes e os métodos de pesquisa em Ciência da Informação, sinalizando caminhos promissores para a automação de etapas metodológicas sem comprometer a qualidade da interpretação científica. Na prática, aponta para o uso estratégico de agentes de IA em atividades como triagem inicial de artigos, identificação de padrões e extração de metadados, com vistas a otimizar tempo e esforço em processos investigativos.
A implementação técnica, realizada com o uso das bibliotecas CrewAI, langchain_openai e PyPDFLoader, demonstrou-se eficaz ao permitir a leitura semiautônoma de documentos acadêmicos e a extração sistemática de informações segundo critérios analíticos predefinidos. O modelo YAML adotado como formato de saída assegurou a padronização dos resultados, facilitando sua integração com fluxos de análise posteriores. A preocupação ética foi evidenciada na definição de diretrizes para a linguagem neutra, a originalidade textual e o respeito aos direitos autorais dos autores analisados.
Entre as limitações, destaca-se a análise aplicada a um número restrito de artigos, o que limita a generalização dos achados. Além disso, o desempenho do agente depende diretamente da qualidade e clareza do texto analisado, o que pode comprometer os resultados em estudos menos estruturados ou mal redigidos.
Futuras pesquisas devem ampliar a base empírica, testar a arquitetura proposta em outros domínios científicos e investigar formas de combinar a atuação de múltiplos agentes com diferentes especializações. Também é recomendável o desenvolvimento de métricas que avaliem não apenas a precisão das extrações, mas a profundidade interpretativa das respostas geradas.
Conclui-se que a integração de agentes de inteligência artificial ao processo de análise científica pode representar um avanço metodológico relevante, especialmente quando articulada a práticas reflexivas e ao julgamento humano. Este estudo oferece uma base sólida para o uso ético, responsável e epistemologicamente ancorado da IA na produção e organização do conhecimento científico.


